Generate consensus LD50 values
Maggie Douglas
Last updated: 2019-07-24
Purpose
Aggregate ECOTOX LD50 data and PPDB LD50 data to generate a consensus list of values for all insecticides in the USGS pesticide dataset.
Libraries & functions
library(tidyverse)
library(scales)
library(readxl)
library(GGally)
# function to calculate geometric mean
gm_mean <- function(x){
exp(mean(log(x)))
}
# function to standardize compound names to uppercase with no special characters
cmpd_std <- function(x){
toupper(gsub(",|-| ","",x))
}
# store today's date
today <- "20190625"Load EPA data
data_clean <- read.csv("../output/ecotox_ld50_apis_mellifera_20170731_clean.csv")
str(data_clean)'data.frame': 1643 obs. of 27 variables:
$ X : int 1 2 3 4 5 6 7 8 9 10 ...
$ cas : int 50293 50293 50293 50293 51036 52686 55389 56382 56724 56724 ...
$ cmpd_epa : Factor w/ 443 levels "(1-Methylethyl)phosphoramidic acid ethyl-3-methyl-4-(methylthio)phenyl ester",..: 73 73 73 73 252 391 387 421 412 412 ...
$ species : Factor w/ 5 levels "Apis mellifera",..: 1 1 1 1 1 1 1 1 1 1 ...
$ sp_common : Factor w/ 5 levels "Carniolan Honey Bee",..: 4 4 4 4 4 4 4 4 4 4 ...
$ org_source : Factor w/ 5 levels "Captive breeding colony",..: 3 3 3 4 3 3 3 4 3 3 ...
$ stage : Factor w/ 2 levels "Adult(s)","EPA/unknown": 2 2 2 1 2 2 2 1 1 1 ...
$ exp_days : num 2 2 2 1 2 2 2 1 1 1 ...
$ form : Factor w/ 4 levels "Active ingredient",..: 3 3 3 1 1 1 1 1 2 1 ...
$ n : int NA NA NA NA NA NA NA NA NA NA ...
$ dose_min : int NA NA NA NA NA NA NA NA 8 5 ...
$ exp_type : Factor w/ 8 levels "Dermal","Diet, unspecified",..: 8 8 7 1 8 8 8 1 2 8 ...
$ exp_grp : Factor w/ 2 levels "contact","oral": 1 1 2 1 1 1 1 1 2 1 ...
$ ld50_op : Factor w/ 4 levels "<","<=",">","~": NA NA NA NA 3 NA NA NA NA NA ...
$ ld50_min_op : logi NA NA NA NA NA NA ...
$ ld50_max_op : logi NA NA NA NA NA NA ...
$ ld50_ugbee : num 6.4 3.9 3.7 13.7 11 ...
$ ld50_min_ugbee: num NA NA NA NA NA ...
$ ld50_max_ugbee: num NA NA NA NA NA ...
$ range_units : Factor w/ 5 levels "CI","CI_95","EPA/unknown",..: NA NA NA NA NA NA NA NA NA 2 ...
$ method : Factor w/ 5 levels "European and Mediterranean Plant Protection Organization",..: 5 5 5 2 5 5 5 2 2 2 ...
$ ref : int 344 344 344 35123 344 344 344 35123 101175 119503 ...
$ cmpd_usgs : Factor w/ 488 levels "1METHYLCYCLOPROPENE",..: NA NA NA NA 359 469 NA 338 NA NA ...
$ cat : Factor w/ 6 levels "F","FUM","H",..: NA NA NA NA 5 4 NA 4 NA NA ...
$ cat_grp : Factor w/ 105 levels "F-1","F-11","F-12",..: NA NA NA NA 104 80 NA 80 NA NA ...
$ class : Factor w/ 152 levels "1,2,4-thiadiazoles",..: NA NA NA NA 146 83 NA 83 NA NA ...
$ grp_source : Factor w/ 4 levels "FRAC","HRAC",..: NA NA NA NA 4 3 NA 3 NA NA ...# Recode operators into three groups
data_clean$ld50_op <- sapply(data_clean$ld50_op, as.character)
data_clean$ld50_op[is.na(data_clean$ld50_op)] <- "="
data_clean$ld50_op[data_clean$ld50_op=="~"] <- "="
data_clean$ld50_op[data_clean$ld50_op=="<="] <- "<"
with(data_clean, table(ld50_op))ld50_op
< = >
5 1219 419 # Recode operators into words (hard to code with these symbols)
data_clean$op_chr <- recode(data_clean$ld50_op,
"=" = "equal",
">" = "greater",
"<" = "less")Load PPDB data
data_ppdb <- read_excel("../data/ppdb_ld50_20180716.xlsx", 1,
col_types = c("text", "text", "text", "text",
"numeric","text", "text", "text")) %>%
filter(!is.na(ld50_ugbee))
str(data_ppdb)Classes 'tbl_df', 'tbl' and 'data.frame': 649 obs. of 8 variables:
$ cmpd_usgs : chr "24D" "24D" "24DB" "6BENZYLADENINE" ...
$ cmpd_ppdb : chr "2,4-D" "2,4-D" "2,4-DB" "6-benzyladenine" ...
$ exp_grp : chr "contact" "oral" "oral" "contact" ...
$ ld50_op : chr ">" "=" ">" ">" ...
$ ld50_ugbee: num 100 94 100 100 58.7 ...
$ source : chr "A" "A" "A" "A" ...
$ qual : chr "5" "5" "5" "5" ...
$ notes : chr NA NA NA "located in biopesticide database" ...# Recode operators into words (hard to code with these symbols)
data_ppdb$op_chr <- recode(data_ppdb$ld50_op,
"=" = "equal",
">" = "greater",
"<" = "less")Join PPDB to category info
# Load category key & add combined category/class column
# See metadata in excel file for how it was generated
cat_key <- read_excel("../keys/USGS_Pesticide-Category.xlsx",1)
head(cat_key, 10)# A tibble: 10 x 7
compound compound_cty compound_2017 category class group source
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 1METHYLCYC… 1-METHYLCYCLO… 1-METHYLCYCLO… PGR unclass… NC none
2 24D 2,4-D 2,4-D H Phenoxy… O HRAC
3 24DB 2,4-DB 2,4-DB H Phenoxy… O HRAC
4 6BENZYLADE… 6-BENZYLADENI… 6-BENZYLADENI… PGR biologi… NC none
5 ABAMECTIN ABAMECTIN ABAMECTIN I avermec… 6 IRAC
6 ACEPHATE ACEPHATE ACEPHATE I organop… 1B IRAC
7 ACEQUINOCYL ACEQUINOCYL ACEQUINOCYL I unclass… 20B IRAC
8 ACETAMIPRID ACETAMIPRID ACETAMIPRID I neonico… 4A IRAC
9 ACETOCHLOR ACETOCHLOR ACETOCHLOR H Chloroa… K3 HRAC
10 ACIBENZOLAR ACIBENZOLAR ACIBENZOLAR F benzo-t… P01 FRAC # Create new variable that is Category-Group
cat_key$cat_grp <- sub('-NA$', '',
paste(cat_key$category, cat_key$group,
sep = "-"))
# Remove unnecessary columns
cat_key_slim <- select(cat_key,
cmpd_usgs = compound,
cat = category,
cat_grp = cat_grp,
class = class,
grp_source = source)
# Merge USGS names and categories with LD50 dataset
# Ignore warning - just converting factor to character vector
data_ppdb_cat <- left_join(data_ppdb, cat_key_slim, by="cmpd_usgs")
str(data_ppdb_cat)Classes 'tbl_df', 'tbl' and 'data.frame': 649 obs. of 13 variables:
$ cmpd_usgs : chr "24D" "24D" "24DB" "6BENZYLADENINE" ...
$ cmpd_ppdb : chr "2,4-D" "2,4-D" "2,4-DB" "6-benzyladenine" ...
$ exp_grp : chr "contact" "oral" "oral" "contact" ...
$ ld50_op : chr ">" "=" ">" ">" ...
$ ld50_ugbee: num 100 94 100 100 58.7 ...
$ source : chr "A" "A" "A" "A" ...
$ qual : chr "5" "5" "5" "5" ...
$ notes : chr NA NA NA "located in biopesticide database" ...
$ op_chr : chr "greater" "equal" "greater" "greater" ...
$ cat : chr "H" "H" "H" "PGR" ...
$ cat_grp : chr "H-O" "H-O" "H-O" "PGR-NC" ...
$ class : chr "Phenoxy-carboxylic-acid" "Phenoxy-carboxylic-acid" "Phenoxy-carboxylic-acid" "biological" ...
$ grp_source: chr "HRAC" "HRAC" "HRAC" "none" ...Combine ECOTOX and PPDB
## Clean up EPA data
data_epa_clean <- data_clean %>%
filter(!is.na(ld50_ugbee) &
cat=="I") %>% # remove rows with NA for LD50 & choose only insecticides
mutate(data_source = ifelse(ref==344, "epa", "ecotox")) %>%
select(cat, cat_grp, grp_source, cmpd_usgs, exp_grp, op_chr, ld50_op, ld50_ugbee, data_source)
## Clean up PPDB data
data_ppdb_clean <- data_ppdb_cat %>%
filter(!is.na(ld50_ugbee) &
cat=="I") %>% # remove rows with NA for LD50 & choose only insecticides
mutate(data_source = ifelse((source=="A" & qual=="5"), "eu", "ppdb")) %>%
select(cat, cat_grp, grp_source, cmpd_usgs, exp_grp, op_chr, ld50_op, ld50_ugbee, data_source)
## Create full dataset
data_clean <- rbind(data_epa_clean, data_ppdb_clean) %>%
mutate(qual = ifelse(data_source %in% c("epa", "eu"), "high", "unknown"))
data_clean <- as.data.frame(data_clean)Create dataset to compare
epa <- data_clean %>%
filter(data_source=="epa") %>%
group_by(cmpd_usgs, exp_grp) %>%
summarise(ld50_epa = log10(gm_mean(ld50_ugbee)))
eu <- data_clean %>%
filter(data_source=="eu") %>%
group_by(cmpd_usgs, exp_grp) %>%
summarise(ld50_eu = log10(gm_mean(ld50_ugbee)))
ppdb <- data_clean %>%
filter(data_source %in% c("eu","ppdb")) %>%
group_by(cmpd_usgs, exp_grp) %>%
summarise(ld50_ppdb = log10(gm_mean(ld50_ugbee)))
ecotox <- data_clean %>%
filter(data_source %in% c("epa","ecotox")) %>%
group_by(cmpd_usgs, exp_grp) %>%
summarise(ld50_eco = log10(gm_mean(ld50_ugbee)))
comp <- epa %>%
full_join(eu, by = c("cmpd_usgs","exp_grp")) %>%
full_join(ppdb, by = c("cmpd_usgs","exp_grp")) %>%
full_join(ecotox, by = c("cmpd_usgs","exp_grp")) Compare estimates
ggpairs(comp[c(3:6)]) +
theme_classic()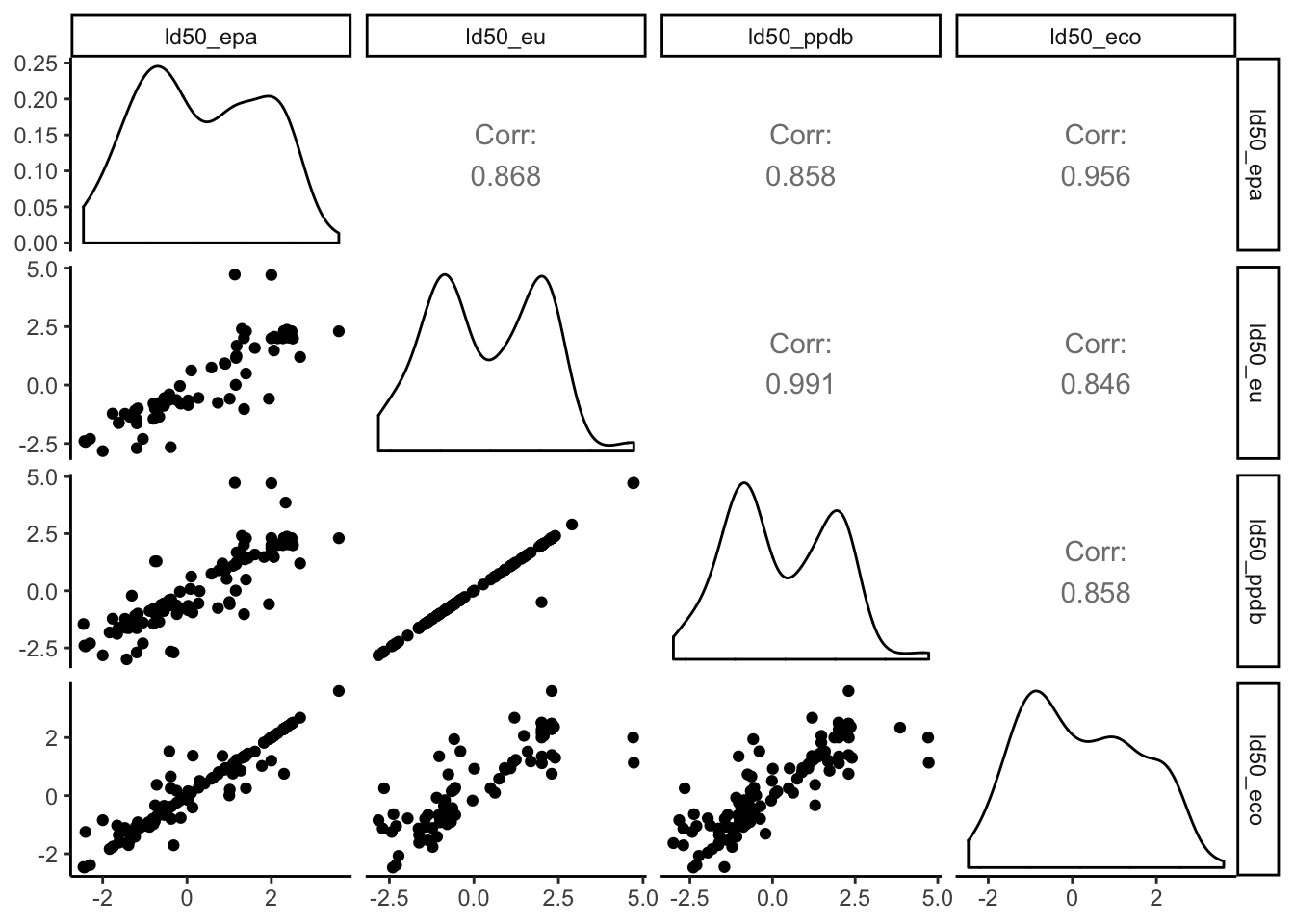
Split the data
# Split by group (contact, oral) and operator
data_split <- split(data_clean,
drop=TRUE,
list(data_clean$op_chr,
data_clean$exp_grp,
data_clean$qual))Aggregate LD50 data
# Create function to generate aggregated data for each list
aggregate <- . %>%
group_by(cmpd_usgs) %>%
summarise(ld50_op = unique(ld50_op),
ld50_mean = gm_mean(ld50_ugbee),
ld50_med = median(ld50_ugbee, na.rm=TRUE),
ld50_max = max(ld50_ugbee, na.rm=TRUE),
ld50_min = min(ld50_ugbee, na.rm=TRUE),
ld50_n = length(ld50_ugbee),
epa_n = length(which(data_source == "epa")),
eu_n = length(which(data_source == "eu")),
eco_n = length(which(data_source == "ecotox")),
ppdb_n = length(which(data_source == "ppdb")),
exp_grp = unique(exp_grp)) %>%
filter(!is.na(cmpd_usgs))
# Apply the function to each list (combo of oral/contact, high/low quality, and point/unbounded estimate)
data_agg <- lapply(data_split, aggregate)Put aggregated data back together
# Store compound names
ins_cmpd <- filter(cat_key, category == "I") %>%
select(compound) %>%
rename(cmpd_usgs = compound)
## Assemble a contact toxicity dataset first with point estimates, then with unbounded estimates for those compounds that don't have point estimates
# Store lists of compounds in each subset (prob. a better way to do this, but I'm not sure what it is)
equal_ct_high <- data_agg$equal.contact.high["cmpd_usgs"]
equal_or_high <- data_agg$equal.oral.high["cmpd_usgs"]
less_ct_high <- data_agg$less.contact.high["cmpd_usgs"]
less_or_high <- data_agg$less.oral.high["cmpd_usgs"]
greater_ct_high <- data_agg$greater.contact.high["cmpd_usgs"]
greater_or_high <- data_agg$greater.oral.high["cmpd_usgs"]
equal_ct_unk <- data_agg$equal.contact.unknown["cmpd_usgs"]
equal_or_unk <- data_agg$equal.oral.unknown["cmpd_usgs"]
less_ct_unk <- data_agg$less.contact.unknown["cmpd_usgs"]
less_or_unk <- data_agg$less.oral.unknown["cmpd_usgs"]
greater_ct_unk <- data_agg$greater.contact.unknown["cmpd_usgs"]
greater_or_unk <- data_agg$greater.oral.unknown["cmpd_usgs"]
# Put dataset back together as described above
contact <- data_agg$equal.contact.high %>%
rbind(filter(data_agg$equal.contact.unknown,
!(cmpd_usgs %in% equal_ct_high$cmpd_usgs))) %>%
rbind(filter(data_agg$less.contact.high,
!(cmpd_usgs %in% equal_ct_high$cmpd_usgs) &
!(cmpd_usgs %in% equal_ct_unk$cmpd_usgs))) %>%
rbind(filter(data_agg$greater.contact.high,
!(cmpd_usgs %in% equal_ct_high$cmpd_usgs) &
!(cmpd_usgs %in% equal_ct_unk$cmpd_usgs) &
!(cmpd_usgs %in% less_ct_high$cmpd_usgs))) %>%
rbind(filter(data_agg$less.contact.unknown,
!(cmpd_usgs %in% equal_ct_high$cmpd_usgs) &
!(cmpd_usgs %in% equal_ct_unk$cmpd_usgs) &
!(cmpd_usgs %in% less_ct_high$cmpd_usgs) &
!(cmpd_usgs %in% greater_ct_high$cmpd_usgs))) %>%
mutate(ld50_ugbee = ifelse(ld50_op == "=",ld50_mean,
ifelse(ld50_op == "<", ld50_min,
ld50_max)),
source = ifelse((epa_n > 0 & eu_n > 0), "epa/eu",
ifelse(epa_n > 0 & eu_n == 0, "epa",
ifelse(epa_n == 0 & eu_n > 0, "eu",
ifelse(eco_n > 0 & ppdb_n > 0, "ecotox/ppdb",
ifelse(eco_n > 0 & ppdb_n == 0, "ecotox",
"ppdb")))))) %>%
full_join(ins_cmpd, by="cmpd_usgs") %>%
replace_na(list(exp_grp = "contact")) %>%
select(cmpd_usgs, exp_grp, ld50_op, ld50_ugbee, ld50_n, source)Warning: Column `cmpd_usgs` joining factor and character vector, coercing
into character vector# Similar operation for oral toxicity
# Note there are no high-quality less than oral values
oral <- data_agg$equal.oral.high %>%
rbind(filter(data_agg$equal.oral.unknown,
!(cmpd_usgs %in% equal_or_high$cmpd_usgs))) %>%
rbind(filter(data_agg$greater.oral.high,
!(cmpd_usgs %in% equal_or_high$cmpd_usgs) &
!(cmpd_usgs %in% equal_or_unk$cmpd_usgs))) %>%
rbind(filter(data_agg$less.oral.unknown,
!(cmpd_usgs %in% equal_or_high$cmpd_usgs) &
!(cmpd_usgs %in% equal_or_unk$cmpd_usgs) &
!(cmpd_usgs %in% greater_or_high$cmpd_usgs))) %>%
mutate(ld50_ugbee = ifelse(ld50_op == "=",ld50_mean,
ifelse(ld50_op == "<", ld50_min,
ld50_max)),
source = ifelse((epa_n > 0 & eu_n > 0), "epa/eu",
ifelse(epa_n > 0 & eu_n == 0, "epa",
ifelse(epa_n == 0 & eu_n > 0, "eu",
ifelse(eco_n > 0 & ppdb_n > 0, "ecotox/ppdb",
ifelse(eco_n > 0 & ppdb_n == 0, "ecotox",
"ppdb")))))) %>%
full_join(ins_cmpd, by="cmpd_usgs") %>%
replace_na(list(exp_grp = "oral")) %>%
select(cmpd_usgs, exp_grp, ld50_op, ld50_ugbee, ld50_n, source)Warning: Column `cmpd_usgs` joining factor and character vector, coercing
into character vectorld50_full <- rbind(contact, oral) Save compounds with missing data
missing <- filter(ld50_full, is.na(ld50_ugbee)) %>%
select(cmpd_usgs, exp_grp)Estimate missing values
Add category back into dataset
combined <- left_join(ld50_full, cat_key_slim, by="cmpd_usgs")
combined$cat_grp <- as.factor(combined$cat_grp)
combined$cat_exp_grp <- paste(combined$cat_grp,combined$exp_grp)
head(combined, 10)# A tibble: 10 x 11
cmpd_usgs exp_grp ld50_op ld50_ugbee ld50_n source cat cat_grp class
<chr> <fct> <chr> <dbl> <int> <chr> <chr> <fct> <chr>
1 ABAMECTIN contact = 0.0300 2 epa/eu I I-6 aver…
2 ACEPHATE contact = 1.2 1 epa I I-1B orga…
3 ACETAMIP… contact = 8.09 2 epa/eu I I-4A neon…
4 ALDICARB contact = 0.285 1 epa I I-1A carb…
5 ALPHACYP… contact = 0.033 1 eu I I-3A pyre…
6 AZINPHOS… contact = 0.42 1 epa I I-1B orga…
7 BENDIOCA… contact = 0.428 1 epa I I-1A carb…
8 BIFENAZA… contact = 7.8 1 epa I I-20D uncl…
9 BIFENTHR… contact = 0.0146 1 epa I I-3A pyre…
10 CARBARYL contact = 0.378 2 epa/eu I I-1A carb…
# … with 2 more variables: grp_source <chr>, cat_exp_grp <chr>Calculate medians for each group
# Calculate median/mean LD50 for each group
# First calculate by RAC group
grp_agg <- combined %>%
group_by(cat, cat_grp, exp_grp) %>%
summarise(ld50_med = median(ld50_ugbee, na.rm=TRUE),
ld50_min = min(ld50_ugbee, na.rm=TRUE),
ld50_max = max(ld50_ugbee, na.rm=TRUE),
ld50_n = length(!is.na(ld50_ugbee))) %>%
mutate(cat_exp_grp = paste(cat_grp,exp_grp)) %>%
na.omit() %>%
as.data.frame()
# Then calculate by broader category (for those compounds w/o RAC group)
cat_agg <- combined %>%
group_by(cat, exp_grp) %>%
summarise(ld50_med = median(ld50_ugbee, na.rm=TRUE),
ld50_min = min(ld50_ugbee, na.rm=TRUE),
ld50_max = max(ld50_ugbee, na.rm=TRUE),
ld50_n = length(!is.na(ld50_ugbee))) Estimate missing values
This code creates a new dataset with values from ECOTOX or PPDB if they are available (as processed above), and otherwise fills in missing values using the median LD50 value for the RAC group (if available) or else the median LD50 value for the broader category (insecticide, fungicide, etc.)
y <- NULL
for(i in 1:length(combined$ld50_ugbee))
{
if (!is.na(combined$ld50_ugbee[i])) {
df1 = combined[i,]
temp <- as.data.frame(df1)
temp$ld50_ugbee_new <- temp$ld50_ugbee
temp$source_new <- temp$source
y <- rbind(y,temp)
}
else if (is.na(combined$ld50_ugbee[i]) &
(combined$cat_exp_grp[i] %in% grp_agg$cat_exp_grp)) {
df2 = combined[i,]
temp <- as.data.frame(df2)
ld50 = filter(grp_agg,
cat_grp==df2$cat_grp &
exp_grp==df2$exp_grp)
temp$ld50_ugbee_new <- ld50$ld50_med
temp$source_new <- "rac_med"
y <- rbind(y,temp)
}
else {
df3 = combined[i,]
temp <- as.data.frame(df3)
ld50 = filter(cat_agg,
cat==df3$cat &
exp_grp==df3$exp_grp)
temp$ld50_ugbee_new <- ld50$ld50_med
temp$source_new <- "cat_med"
y <- rbind(y,temp)
}
}
data_full <- y %>%
select(-ld50_ugbee, -source) %>%
rename("ld50_ugbee" = "ld50_ugbee_new",
"source" = "source_new")
# Check final dataset
with(data_full, table(source, exp_grp)) exp_grp
source contact oral
cat_med 1 8
ecotox 5 11
ecotox/ppdb 1 1
epa 45 7
epa/eu 44 20
eu 14 38
ppdb 5 4
rac_med 23 49Export combined LD50 data
filepath <- paste("../output/ld50_usgs_complete_",today,".csv", sep="")
write.csv(data_full, filepath, row.names=FALSE)Session information
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] GGally_1.4.0 readxl_1.3.1 scales_1.0.0 forcats_0.4.0
[5] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1
[9] tidyr_0.8.3 tibble_2.1.3 ggplot2_3.2.0 tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 xfun_0.8 reshape2_1.4.3
[4] haven_2.1.1 lattice_0.20-38 colorspace_1.4-1
[7] generics_0.0.2 vctrs_0.2.0 htmltools_0.3.6
[10] yaml_2.2.0 utf8_1.1.4 rlang_0.4.0
[13] pillar_1.4.2 glue_1.3.1 withr_2.1.2
[16] RColorBrewer_1.1-2 modelr_0.1.4 plyr_1.8.4
[19] munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0
[22] rvest_0.3.4 evaluate_0.14 labeling_0.3
[25] knitr_1.23 fansi_0.4.0 broom_0.5.2
[28] Rcpp_1.0.1 backports_1.1.4 jsonlite_1.6
[31] fs_1.3.1 hms_0.5.0 digest_0.6.20
[34] stringi_1.4.3 grid_3.6.1 cli_1.1.0
[37] tools_3.6.1 magrittr_1.5 lazyeval_0.2.2
[40] crayon_1.3.4 pkgconfig_2.0.2 zeallot_0.1.0
[43] xml2_1.2.0 lubridate_1.7.4 assertthat_0.2.1
[46] rmarkdown_1.14 reshape_0.8.8 httr_1.4.0
[49] rstudioapi_0.10 R6_2.4.0 nlme_3.1-140
[52] compiler_3.6.1 This R Markdown site was created with workflowr